안녕하세요 이번 포스팅은 바로
"너비우선탐색-BFS(Breadth First Search)"
입니다
그래프는 컴퓨터공학과의 경우 자료구조 시간에 배우게 되는데
이때 그래프의 탐색을 같이 배우게 됩니다.
탐색중에 가장 유명한 탐색은
깊이우선탐색인(DFS),너비우선탐색(BFS)입니다.
그래프(Graph)
그래프에 있어서 가장 유명한 것은 바로 konigsberg의 pregel강에 문제이다.
이 다리 문제는 임의의 지역에서 출발해서 모든 다리를 한번만 건너 처음 출발지역으로
돌아올 수 있는 지에 관한 문제였는데 스위스의 수학자 (오일러)Euler가 그래프를 이용해 풀었다.
이를 "오일러 행로"라고 한다.
그래프는 정점(Vertex)와 edge(간선) 두 가지 구성요소를 가지고 있습니다.
또한, 무방향성,방향성 두 가지 종류의 그래프가 있습니다.
- 무방향성 그래프 -
각 간선에 방향성이 존재하는 그래프입니다.
<u,v> : u -> v 간선을 표현합니다.
이 경우 u는 꼬리(tail)이고 v는 머리(head)이다.
- 방향성 그래프 -
vertex의 쌍을 나타내는 간선이 방향성이 없습니다.
(u,v),(v,u) : 동일한 간선을 표현합니다.
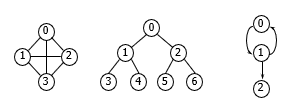
- 그래프 예 -
<1번 그림>
노드 : 0,1,2,3
간선 : (0,1),(0,2),(0,3),(1,2),(1,3),(2,3)
<2번 그림>
노드 : 0,1,2,3,4,5,6
간선 : (0,1),(0,2),(1,3),(1,4),(2,5),(2,6)
<3번 그림>
노드 : 0,1,2
간선 : <0,1>,<1,0>,<1,2>
- 그래프 표현 법 -
<인접행렬>
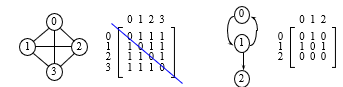
인접행렬의 경우
무방향성 그래프는 1번그림과 같이 대칭성을 보입니다.
반면에 방향성 그래프는 2번그림과 같이 비대칭성을 보입니다.
<인접리스트>

인접리스트의 경우
연결되는 vertex를 한 개의 연결 리스트로 표현합니다.
너비우선탐색(BFS)
- 너비우선탐색을 하는 방법 -
1. 출발 vertex에서 인접한 정점을 방문한다.
2. vertex에 인접한 모든 vertex들을 방문한다.
3. v에 인접한 모든 vertex들을 방문하면서, v에 인접한 첫번째 vertex부터
인접한 vertex중에서 아직 방문하지 않은 vertex들을 차례대로 방문
(이때 Queue를 사용한다)
- 그래프 예제 -

- BFS 풀이 순서 -

위의 보시는 거 처럼 제일 먼저 방문한 vertex를 queue저장합니다.
그 후 visit[vertex]를 true로 만들고 뺀 후 출력합니다.
이렇게 계속 반복해줍니다.
결과 : V0, V1, V2, V3, V4, V5, V6, V7
- 소스코드 -
public class BFS {
public static void main(String arg[]) {
int n, n2, v, w, start;
Scanner sc = new Scanner(System.in);
n = sc.nextInt(); // 정점의 개수
bfs_Node node = new bfs_Node(n);
n2 = sc.nextInt(); // 간선의 개수
for (int i = 0; i < n2; i++) {
v = sc.nextInt();
w = sc.nextInt();
node.put(v, w);
}
start = sc.nextInt(); // 시작점
node.bfs(start);
}
}정점과,간선의 개수를 입력받습니다.
그 후 간선의 개수만큼 간선을 받아줍니다.
이 때 v는 출발, w는 도착점입니다.
void put(int v, int w) {
list[v][w] = 1;
list[w][v] = 1;
}put 함수에서 반복문 수 만큼 v,w를 계속 받아줍니다.
이때 무방향성이기 때문에 w,v 역시 저장해줍니다.
void bfs(int start) {
visit[start] = true;
queue.add(start);
while (queue.size() != 0) {
start = queue.poll();
System.out.print(start + " ");
for (int i = 0; i < visit.length; i++) {
if (list[start][i] == 1 && visit[i] != true) {
queue.add(i);
visit[i]=true;
}
}
}
}시작점을 저장하고 queue에 저장합니다.
그 후 queue.size를 통해 저장된 게 없을 때 까지 계속 반복해줍니다.
정점의 개수만큼 for문을 돌려줍니다.
그리고 queue의 저장된 수를 하나 뺀 후 출력합니다.
그 후 조건문에서 인접하고 아직 방문하지 않는 정점을 queue에 저장시켜 줍니다.
그리고 true로 바꿔 다시 그 정점에 방문하지 않도록 합니다.
- 최종 소스코드 -
import java.util.Scanner;
import java.util.LinkedList;
import java.util.Queue;
public class BFS {
public static void main(String arg[]) {
int n, n2, v, w, start;
Scanner sc = new Scanner(System.in);
n = sc.nextInt(); // 정점의 개수
bfs_Node node = new bfs_Node(n);
n2 = sc.nextInt(); // 간선의 개수
for (int i = 0; i < n2; i++) {
v = sc.nextInt();
w = sc.nextInt();
node.put(v, w);
}
start = sc.nextInt(); // 시작점
node.bfs(start);
}
}
class bfs_Node {
int[][] list, n;
boolean[] visit;
Queue<Integer> queue = new LinkedList<>();
bfs_Node(int n) {
list = new int[n][n];
visit = new boolean[n];
}
void put(int v, int w) {
list[v][w] = 1;
list[w][v] = 1;
}
void bfs(int start) {
visit[start] = true;
queue.add(start);
while (queue.size() != 0) {
start = queue.poll();
System.out.print(start + " ");
for (int i = 0; i < visit.length; i++) {
if (list[start][i] == 1 && visit[i] != true) {
queue.add(i);
visit[i]=true;
}
}
}
}
}소스코드는 정답이 없기 때문에 참고만 하시고 원하는 식으로 코드를 작성하시면 됩니다.
이상으로 오늘은 그래프의 탐색중 너비우선탐색(BFS)에 대해 알아보았습니다.
이해가 안되거나 궁금한 사항이 있으면 댓글로 남겨주시면 됩니다.
읽어주셔서 감사합니다.
'자바' 카테고리의 다른 글
| [자료구조] 자바 - 큐(Queue)이란? (0) | 2021.02.02 |
|---|---|
| [자료구조] 자바 - 스택(Stack)이란? (0) | 2021.01.26 |
| (java)자바 깊이우선탐색(DFS) (0) | 2021.01.14 |
| 백준 알고리즘 문제_1004번(자바) (0) | 2021.01.08 |
| 백준 알고리즘 문제_1003번(자바) - 시간초과 해결 (0) | 2021.01.06 |